In this post, we will be taking an in-depth look at data-modelling and how best to solve some common data-modelling problems.
What is Data-Modelling..?
The simplest definition of data-modelling is that it is the act of deciding what table structure you need to best represent your data in a relational database.
In this post the terms table, entity and relation are used interchangably and, for our purposes, refer to an Access table.
When you create tables in Microsoft Access, you are data-modelling. When you are trying to work out whether you should have a single table for employees or different tables for employees and supervisors (hint: single table), you are data-modelling. When you are not sure if Clients are, in fact, Organisations, you are data-modelling.
..and why does it matter?
You may have found yourself in the situation in which you need to create a database using Microsoft Access (or any other software that utilises a relational database). Your first thought may have been to quickly assemble the tables, fill them with some seed data and then move onto the queries, forms and reports. This works well for a month or so…
Only you now have a problem. You can’t quite work out how to invoice both an Organisation and an Individual. Or you may wish to give every member of staff a supervisor but are unsure how to achieve this whilst maintaining relational integrity (this simply means that your data isn’t garbage). You get the sneeking suspicion that you have spent too little time data-modelling and moved onto other areas of your database too quickly. And guess what? You have.
Traditional database theory (and this is just a theory so don’t get too dogmatic here) is that you should spend 1/3 of your time data-modelling, 1/3 writing code and 1/3 writing tests. For all its virtues, the one thing that you cannot do with MS Access, is write a test. So, in reality that means that you should have spent 1/2 of your time data modelling and 1/2 writing code! And did you? Hell no.
It is an unfortunate problem with those new to MS Access (and some that are not quite so new) that they rush the single most important part of creating a database; data-modelling. So why does it matter?
Think of building an MS Access project like building a house. You start with the blueprint for the foundations, then you lay the foundations, then you build the house. What would happen if you wanted to build a 3-storey house but only had a foundation strong enough to hold a 2-storey house? What would happen if you hadn’t quite made the foundations wide enough for the walk-though kitchen, dining-room or lounge? Well, you would have to knock the house down and start again (or live in your sub-optimal house). In this analogy, the house itself are the queries, forms and reports, the foundation is the tables and the blueprint is the data-model (oh and by the way, this isn’t just a problem for MS Access developers; any relational database technology requires a sound approach to data-modelling).
When a database is created, the queries, forms and reports are all built upon the table structure and they exist to either input the data into a table, query the data in a table or output the data from a table. If the table changes, the queries, forms and reports change. All of them. Everytime. So, if you make a mistake with your data-model and only realise this after 3 months of development, you are going to need to modify many more objects than the table(s) themselves. This practice is both frustrating and time consuming. It is the epitome of unproductiveness.
Since data-modelling is absolutely vital to the health of your MS Access application, the very first thing we need to do is to understand what a relational database is and why it is important for storing data.
What is a Relational Database?
Let’s start with a simple scenario. You have a database that you use to track orders (you place an order with a supplier, the supplier delivers it to a certain address, you log that it has been delivered) and you use an Excel sheet that looks like this:
![]()
You decide that because you have heard a lot of good things about relational databases, you want to stop using Excel and start using MS Access and so you import the Excel sheet above and create a new table called Orders. What’s wrong with that? You are now using a relational database and your table does at least have an extra ID field for each order.
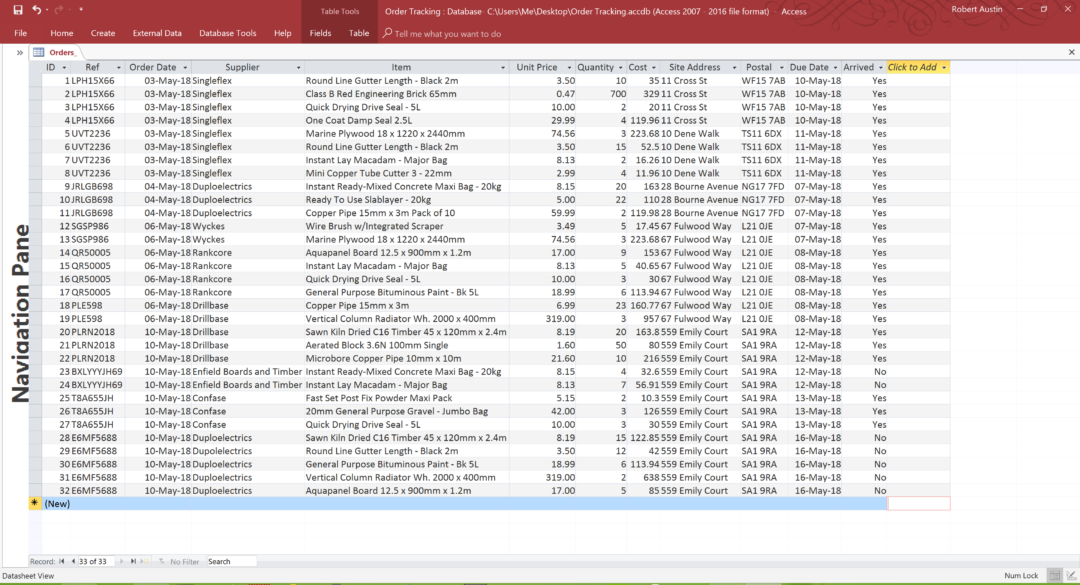
MS Access project with a single “Orders” table
In truth, importing an Excel sheet and creating a single MS Access table solves none of the problems that you might find associated with using an Excel sheet in the first place. And they are…
Updating Existing Data
We often need to update data (such as the address details of an Organisation, or even the Organisation’s name). When performing an update, we want to make sure that all instances that require updating are updated.
Let’s look at a simple example using the table above. In the Orders table, there is a Supplier called Duploelectrics that is featured in multiple orders. What would happen if Duploelectrics changed its name to something equally ridiculous such as ElectricDuplos?
Well, you would have 2 options.
Option 1
The first option would be to enter ElectricDuplos as a new Supplier. This would mean that all historic data would be untouched and, from now on, when new data is added, it is added under the new Supplier name. This is a fairly simple solution. But! What if you want to know how many orders have been placed with Duploelectrics/ElectricDuplos since the database began? This kind of information requires querying the database for all orders for Duploelectrics/ElectricDuplos and then aggregating them. In this case, the 2 different names of the company would make it difficult to query the database for useful information.
Option 2
So, if entering a new Supplier name is not a good idea, what else can be done? The second option is to run an update query and everywhere you see the name Duploelectric replace it with ElectricDuplos. This is slightly tiresome but at least it would get the job done. The only problem is that it wouldn’t work. Take a look at the row with an ID of 29 in the Access table above.
We have accidently misspelt the name Duploelectrics as Dupolelectrics! This particular entry would not update and the only thing we could really do would be to go through the database trying to find misspellings (good luck with that). Now, in the table above, we only have a small number of rows to work with but imagine if we had a table with 100,000 rows of data.
Would we be able to find every instance of a misspelt supplier name? Could we ever be sure that the value of all orders placed by a given supplier was correct? Or might we worry that a misspelt supplier name means we have missed important information?
Reducing File Size
Another area where a relational database could help us would be in the ability to keep the size of the database application down. Let’s continue imagining that we had a database of 100,000 records and think about the effect that that would have on the size of a table.
If, as in the above table, we have to store the full name of the supplier everywhere that it appears (such as Duploelectrics in the Orders table), we need space to hold 14 characters per entry! This would quickly lead to database bloat and a file that increases its size very rapidly.
We have identified two areas in which the use of a single table to store data can cause potential problems. What can we do to mitigate these issues?
An answer to the above problems
Imagine if we were able to store a simple number for a Supplier instead of the full name and that that number referred to the relevant Supplier (such as Duploelectrics).
Well, we can, and it is a feature of relational databases that makes them so effective. Take a look at this table to better understand our point:
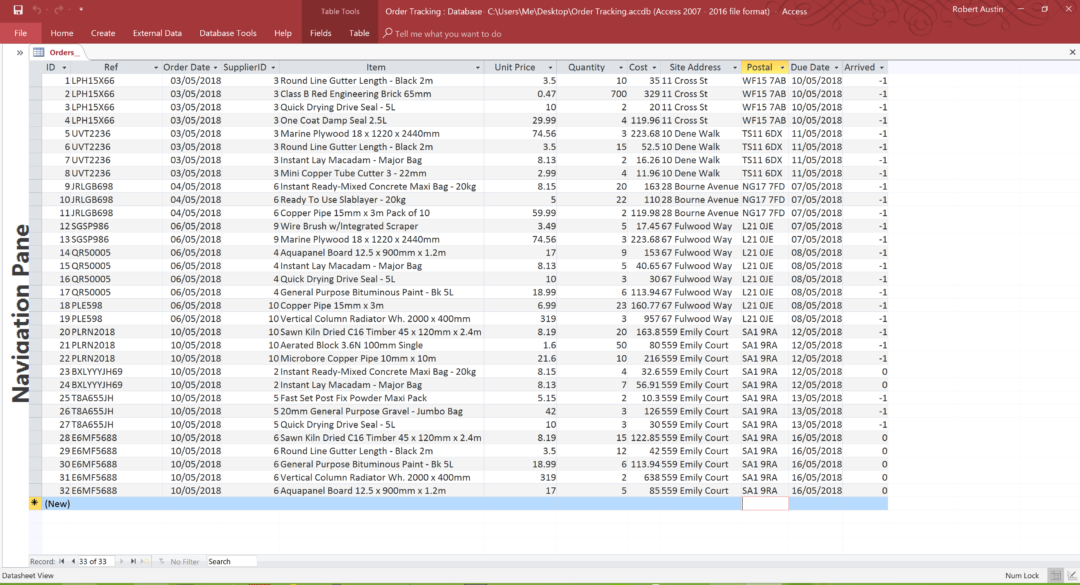
Orders table with SupplierID column in place of Supplier column
In the above table, we have replaced the Supplier column with the SupplierID column. This means that Duploelectrics is now being represented with its ID (6 in this case) instead of the full company name. Now, as rows are added, we are minimsing the increase of the size of the table.
The Suppliers themselves will be stored in their own table:
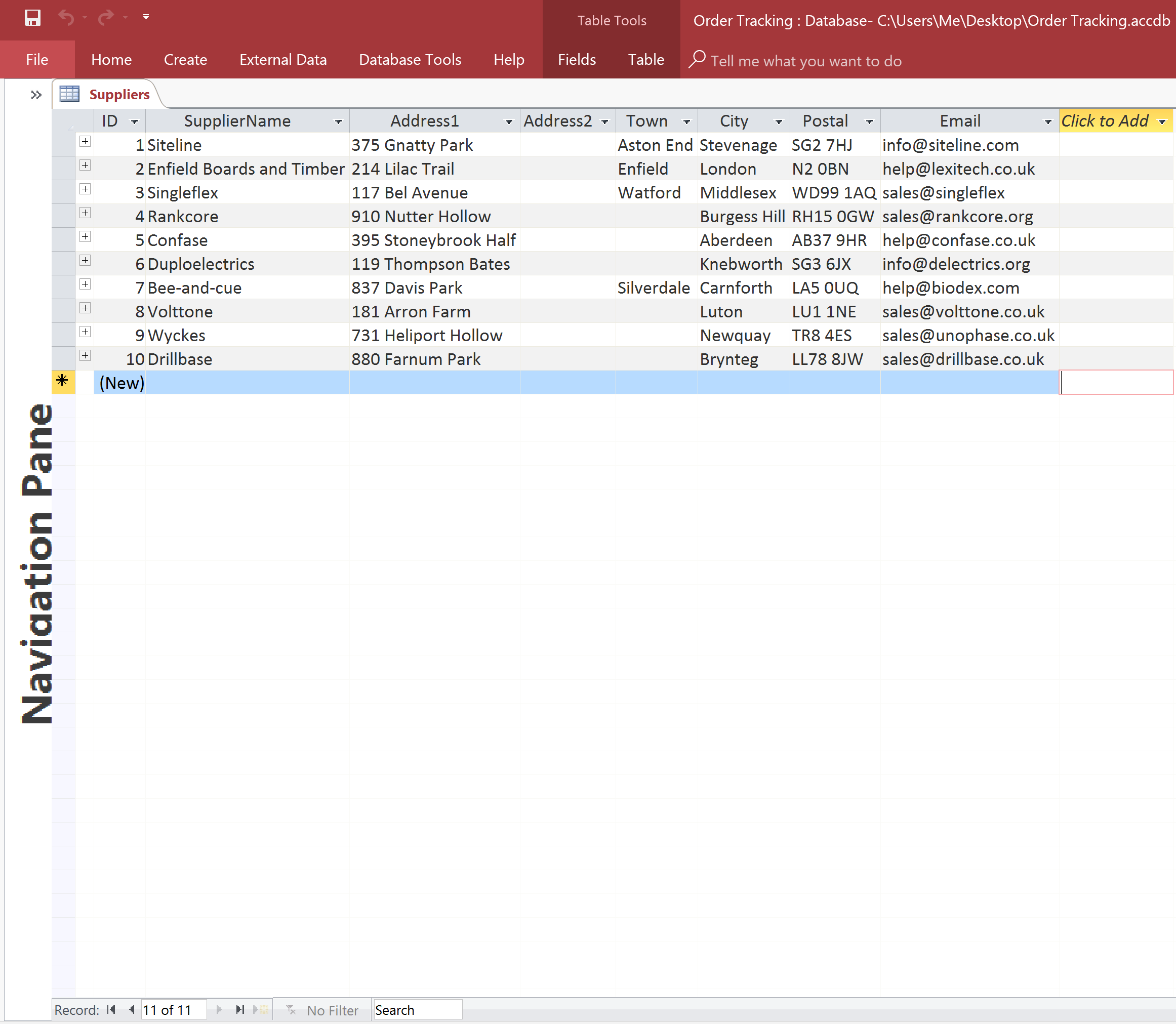 The Supplier’s Table
The Supplier’s Table
Storing individual entities in their own tables and referencing them in other tables using ID fields is fundamental to the idea behind relational databases. The above structure in which the SupplierID field is stored in the Orders table solves not only the problem of the size of a growing database but also the issue of updating a company’s name. Because we are storing the name Duploelectrics in a single location, we only have one place where we would need to update it. Hurrah!
Another side effect of this structure is that we can easily store meta-data. Meta-data is data about data. In other words (and in this context), the Supplier’s name is the data whilst the Supplier’s address and email are meta-data.
One entity, many places
Although there are many benefits to using a relational database (we have already discussed updating records and reducing bloat), a further benefit is the ability to reference the same entity in multiple tables.
Sticking with our Orders database, let’s say that not all Suppliers stock all the items. So we want to create another table to store information called ItemBySupplier. It could look something like this:
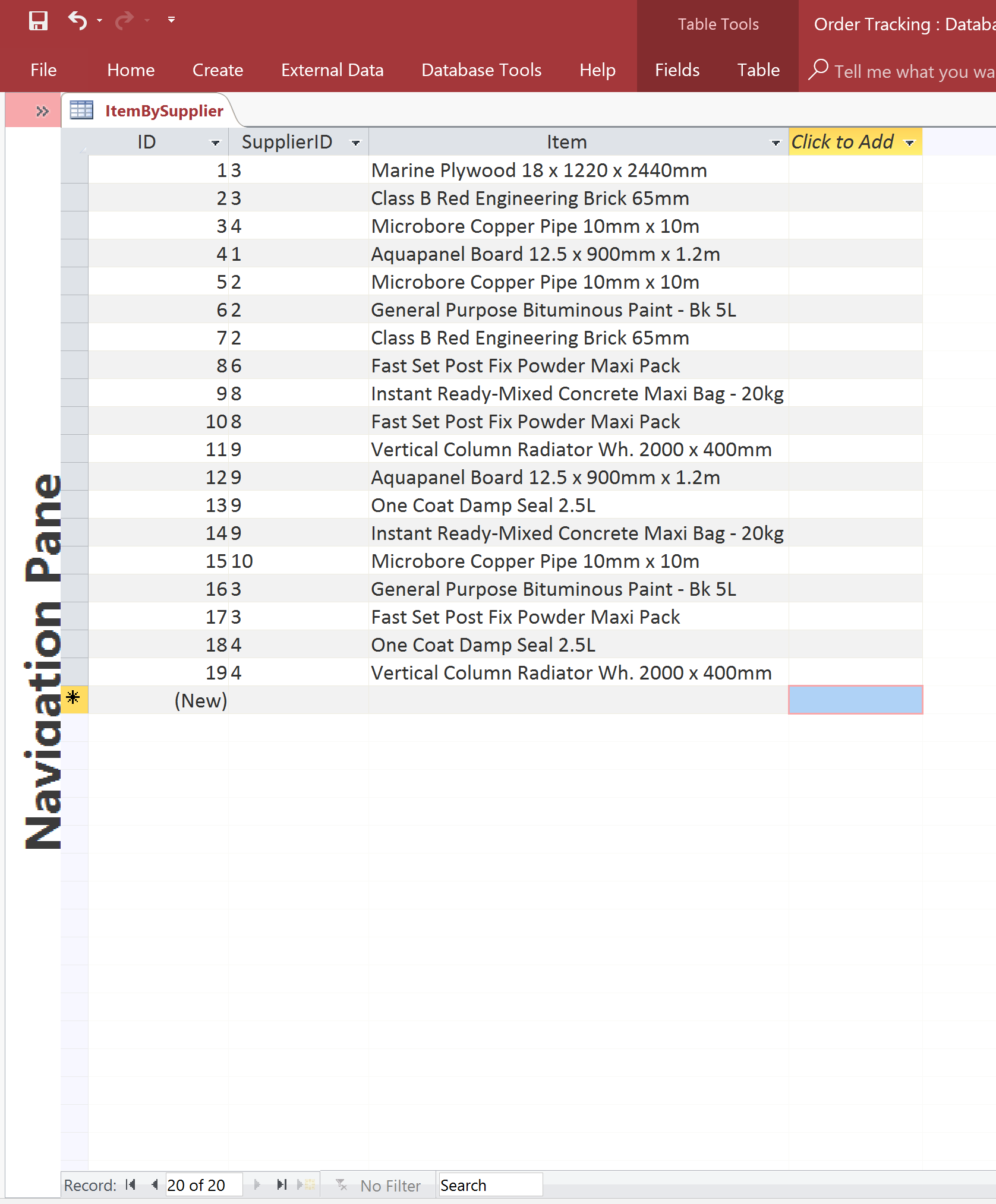 The ItemBySupplier table
The ItemBySupplier table
And we are able to use the same SupplierIDs that we used in the Orders table. Now imagine if we did have to update the name of a Supplier; it would get updated everywhere simultaneously. The ability to define a single entity and reference it in multiple places is another powerful feature of relational databases.
Note: The curious amongst you might well be asking why the Items themselves are not in their own table. And you would be right. They should be. We are trying to explain relational databases in as simple a way as possible so are explaining the relevant concepts step-by-step. But good spot.
So, what should and what should not be in its own table?
Let’s speculate that you have an Excel sheet (or several Excel sheets) that you have been using to track your business activity and wish to start using MS Access. And let’s also speculate that you wish to enjoy the benefits of using a relational database but are not sure exactly how to take an Excel sheet and convert it into a set of tables. Well the process that you require is known as normalistion.
An aside: taking an Excel sheet and turning it into a series of tables that store the appropriate entities and their relationships is data-modelling. Normalisation is a structured form of data-modelling where you work backwards from some form of list and create the appropriate table structure.
Normalisation revolves around the idea of deconstructing a list of data (such as our Orders list) and converting the data into different tables. The process is rule driven and must be in done in a particular order.
Why Normalistion is too much
Normalisation is a well-defined process but can become a little technical. Here is an example of what you might find when researching it:
A database is in Second Normal Form if it is in First Normal Form (which requires the use of atomised data in uniquely-named columns) and if it doesn’t contain a Partial Dependency. A Partial Dependency requires that a column relies on part of a composite key rather than the whole composite key. Blah blah blah yawn.
Normalisation requires too much of a theoretical approach to data-modelling to be of much practical use for the vast majority of MS Access users (which largely consist of individuals who were foolish enough to tell their boss that they could create a database for work to solve some problem). If, however, you wish to really get your hands dirty learning normalisation, please try this site or this one.
We prefer to take a more practical approach to data-modelling.
Basic Principles for data-modelling
Instead of using an oh-so-theoretical approach to data-modelling, we provide you with some basic principles that will help you to avoid making costly mistakes and ensure that you build solid foundations into your data structure.
1. Start with Outputs
Let’s begin with a simple definition of what MS Access and other relational databases can do for you. They can take an input (such as details about an Organisation), store it in a table (such as the Organisations table), retrieve and query it (such as a Select query) and turn it into an output (such as a report).
In this context, outputs can be defined as data that has been queried, organised and, potentially, aggregated (and we are fundamentally interested in outputs at this point). It would be simple enough (certainly with MS Access) to refer to them as reports but certain reports are not obviously reports. Take invoices, for example. Would you refer to invoices as reports? Well, maybe or maybe not, but they are certainly outputs.
When it comes to data-modelling, outputs are essential. We can use outputs and work backwards to determine an appropriate data-model. Let’s take a look at a simple example to illustrate our point:
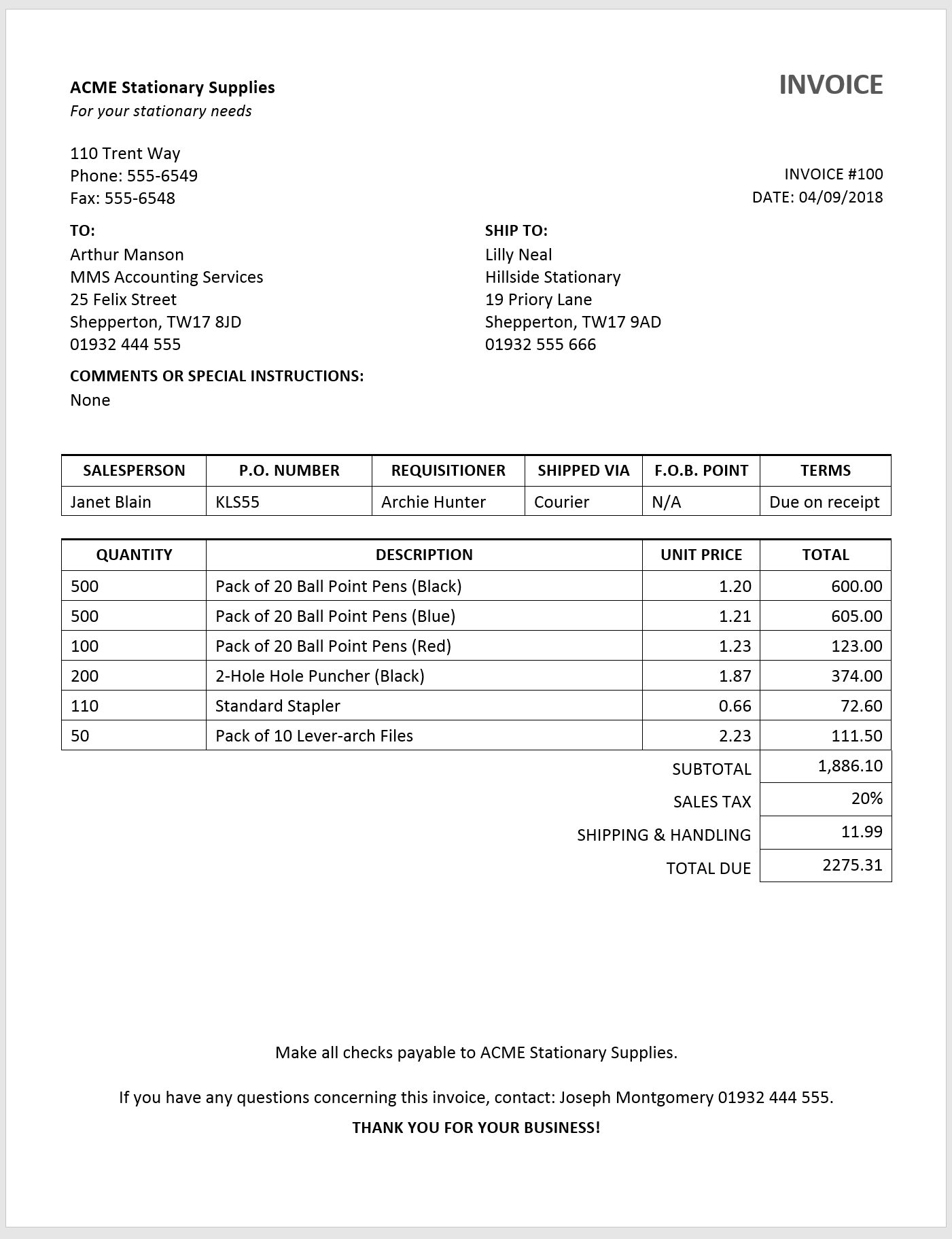
Stationary Invoice
You have been approached by a stationary company (ACME Stationary Supplies) to convert their “invoicing system” (which consists of a single Word document that is constantly reused) into a proper MS Access database. The invoice that is produced from the Word document looks like the invoice above. So, what does this invoice tell us about the data-model we might need to create? It may not be immediately obvious but with some common sense and a little real-world business know-how, we can make great strides in creating a working data-model with a single output such as an invoice.
Let’s start with what is clear from the invoice. Each invoice will contain an:
- Invoice Number.
- Invoice Date.
- Company, contact, name and address that the invoice is intended for (Receiver Address).
- Company, contact, name and address that the goods are being shipped to (Shipping Address).
- Other Information (Salesperson, P.O. Number, etc.)
- Invoice Details
OK, so that is quite a good start. Let’s imagine that we wanted a single table to store all of the above data. What would it look like (we are deliberately keeping the Receiver Address, Shipping Address and Other Info in single fields to keep things simple)?
Invoices
| Invoice No. | Date | Receiver Address | Shipping Address | Other Info | Quantity | Description | Unit Price | Total |
| 100 | 04/09/18 | 25 Felix Street | 25 Priory Lane | KLS55 etc. | 500 | Pack of 20 Ball Point Pens (Black) | 1.20 | 600.00 |
| 100 | 04/09/18 | 25 Felix Street | 25 Priory Lane | KLS55 etc. | 500 | Pack of 20 Ball Point Pens (Blue) | 1.21 | 605.00 |
| 100 | 04/09/18 | 25 Felix Street | 25 Priory Lane | KLS55 etc. | 100 | Pack of 20 Ball Point Pens (Red) | 1.23 | 123.00 |
Now, we know from earlier in the article that we are trying to avoid repeating data and, unfortunately, we are doing just that (invoice number, invoice date, receiver address, etc.) This is a good clue that we should create another table. Let’s keep all of the repeating data in a single table called Invoices and move the non-repeating data to a new table called Invoice Lines (we have added ID fields with arbitrary values for both the Invoices and Invoice Lines tables).
Now we have something like this:
Invoices
| ID | Invoice No. | Date | Receiver Address | Shipping Address | Other Info |
| 25 | 100 | 04/09/18 | 25 Felix Street | 25 Priory Lane | KLS55 etc. |
Invoice Lines
| ID | InvoiceID | Quanity | Description | Unit Price | Total |
| 3 | 25 | 500 | Pack of 20 Ball Point Pens (Black) | 1.20 | 600.00 |
| 4 | 25 | 500 | Pack of 20 Ball Point Pens (Blue) | 1.21 | 605.00 |
| 5 | 25 | 100 | Pack of 20 Ball Point Pens (Red) | 1.23 | 123.00 |
So, we have achieved our objective of avoiding pointlessly repeating data. What next?
Going back to the Invoices table, common sense dictates that the Receiving Company/Address and the Shipping Company/Address may appear in other invoices. If this is the case, would it not make sense to move them to a separate table and reference them in the Invoice table using an ID field? But how many tables? Do we need separate Shipping Company and Receiving Company tables? Or would a single Company/Organisation table suffice? Having weighed this up, we decided to go for a single Organistion table because the meta-information for Shipping and Receiving companies is the same (this is obvious if you look at the table below):
Organisations
| ID | Organisation | Contact | Address1 | Address2 | Town | City | Postcode | Telephone |
| 15 | MMS Accounts | Arthur Manson | 25 Felix Street | Shepperton | TW17 8JD | 01932 444 555 | ||
| 16 | Hillside Stationary | Lilly Neal | 19 Priory Lane | Shepperton | TW17 9AD | 01932 555 666 |
The fields for the Shipping and Receving companies are exactly the same. Therefore, we put them in the same table.
The Invoices table will now look like this:
Invoices
| ID | Invoice No. | Date | ReceiverID | ShippingID | Other Info |
| 25 | 100 | 04/09/18 | 15 | 16 | KLS55 etc. |
Let’s finish by expanding the Other Info column:
Invoices
| ID | Invoice No. | Date | ReceiverID | ShippingID | Salesperson | PONum | Req | ShippedVia | FOB | Terms |
| 25 | 100 | 04/09/18 | 15 | 16 | Janet Blain | KLS55 | Archie Hunter | Courier | N/A | Due on Receipt |
And we are done.
From a single Invoice report output we have worked out that we need 3 tables (Invoices, Invoice Lines and Organisations). We didn’t need to use an overly theoretical approach, just a wish to avoid repeating information and a little bit of common sense!
And if there are no outputs?
An obvious question arises here: What do we do if we do not have outputs? The answer is that either you do, in fact, already have outputs or that you will need to create them. Many MS Access databases began life as a disparate collection of Excel sheets and Word documents and of these, the Word documents, more often than not, contained outputs such as invoices, labels or checklists whilst the Excel sheets may have contained business analysis, aggregated revenues and budget reports. There are all informative when it comes to creating a data-model and can, in fact, be classified as outputs.
If you do not have these types of output then make them. The whole point of any database is to, at some point, present organised, aggregated data to the user. If you are creating a database to easily generate invoices then invoices are your output. If you are creating a database to print multiple address labels for attaching to envelopes then the address labels are your outputs. If you are creating a database to track progress on a series of projects then a project summary report is your output. If you have no outputs then recognising what your outputs should be is the best place to start.
If you genuinely have nothing more than an idea and not a single output then start your database off manually using Excel and Word to track your information. Manually use Word to create your Invoices or Summary reports. Try and track your sales through Excel and then try and use Excel‘s analysis tools to aggregate them. The insights you gain from manually creating your outputs will be invaluable in the creation of your relational Access database. In fact, you can consider the creation of outputs as the very first step in data-modelling.
2. Use Atomised Data
The second rule you should follow is to use Atomised Data. Atomised Data is a fancy way of saying that every field in a table should contain a single value. Take a look at this table and try and spot the non-atomised field:
Organisations
| ID | Organisation | Address1 | Telephone |
| 1 | Siteline | 375 Gnatty Park | 01935 665 811, 01935 665 812 |
| 2 | SingleFlex | 214 Bel Avenue | 555-3215, 555-6956, 555-2145 |
| 3 | Rankcore | 910 Nutter Hollow | 01932 552 841 |
Hopefully, you spotted that the Telephone field contains non-atomised data (users are entering more than one telephone number in the field).
Why is this a specific problem?
The reason that non-atomised data is an issue, is because when it comes to creating things like Invoices, you end up with problems like this:
 Shipping Address for Invoice
Shipping Address for Invoice
Take a look at the Shipping Address for an invoice in which multiple telephone numbers have been stored in a single field. These multiple telephone numbers are now being shown on the invoice and it should be obvious that this is not an acceptable way of presenting an invoice to a client.
Another reason that fields storing multiple values is bad is that it is just not specific enough. An Organisation may have multiple telephone numbers (or indeed email addresses) but more often than not, this is not for nothing. It is very probable that the Organisation in question has a telephone number for sales, another for account enquiries, another for technical support (this is obviously industry dependent but you get the idea). Filling a single field with multiple forms of the same data doesn’t tell us enough about the individual forms of data. Which telephone number do you use to report a missing delivery? Which one do you use for account enquiries? These are relevant questions and worth considering when creating a data-model.
This brings to the obvious question of what is the most “correct” way of solving this problem. And that brings us neatly on to our next database principle:
3. Tables should expand down, not across
If we follow on with the telephone number example, how exactly do we store multiple telephone numbers? One of the most common ways of answering this question is also the most common mistake that newbie programmers make when it comes to data-modelling. Let’s say you have decided on this approach to store multiple telephone numbers:
Organisations
| ID | Organisation | Address1 | Telephone 1 | Telephone 2 | Telephone 3 |
| 1 | Siteline | 375 Gnatty Park | 01935 665 811 | 01935 665 812 | |
| 2 | SingleFlex | 214 Bel Avenue | 555-3215 | 555-6956 | 555-2145 |
| 3 | Rankcore | 910 Nutter Hollow | 01932 552 841 |
In the above table, the developer has added 2 extra fields to store telephone numbers. This has successfully solved the issue of using non-atomised data but has created another issue. Consider this question:
What happens if an organisation has 4 telephone numbers?
There are several possible answers.
- Don’t allow the company to have a 4th telephone number.
- Add the 4th telephone number into Telephone 3 and use non-atomised data in that field (but just that field).
- Add another field to the table.
For the record, all of the above answers are wrong and that is because there is no right answer. We have a bad data-model and nothing will solve that other than remodelling the table.
Here are the reasons why:
- Don’t allow the company to have a 4th telephone number – If you won’t allow a company to give you a 4th telephone number why did you allow the second and third? Why not be strict and say that you only ever want a single telephone number for an Organisation? Who cares if there are 4 departments, right?
- Add the 4th telephone number into Telephone 3 and use non-atomised data in that field (but just that field) – This structure was meant to avoid non-atomised data so adding non-atomised data makes no sense at this point.
- Add another field to the table – If you add another field to the table, you will need to update all associated objects. Every query, form, report, macro, code block, etc. will need updating. And what happens if you spend a day doing that and your client/boss informs you that he/she would like to store a fifth telephone number? Arghhh!
Just to really drive the point home as to why the “columns across” solution is a terrible idea, think of all the wasted space. Not every company has 2 or 3 numbers, yet you have some dedicated space for every single company for those fields.
Of all the mistakes that can be made when data-modelling, this is the possibly the most heinous. Just don’t do it. Remember that tables expand downwards not across.
And finally, the correct way to store multiple email addresses is to use… another table! Perhaps a common theme is emerging here. But what would the associated tables look like?
Organisations
| ID | Organisation | Address1 |
| 1 | Siteline | 375 Gnatty Park |
| 2 | SingleFlex | 214 Bel Avenue |
| 3 | Rankcore | 910 Nutter Hollow |
Telephone Numbers
| ID | OrganisationID | Telephone | Type |
| 1 | 1 | 01935 665 811 | Sales |
| 2 | 1 | 01935 665 812 | Accounts |
| 3 | 2 | 555-3215 | Enquiries |
| 4 | 2 | 555-6956 | Accounts |
| 5 | 2 | 555-2145 | Sales |
| 6 | 3 | 01932 552 841 | Sales |
So far, the solution to a lot of data-modelling issues has been to remodel by adding another table.
Let’s take a look at an example where adding another table is not necessarily the right answer…
4. Self-referencing Tables Explained
Let’s outline a common scenario that can cause problems in databasing. You have an entity such as a Staff table which looks like this:
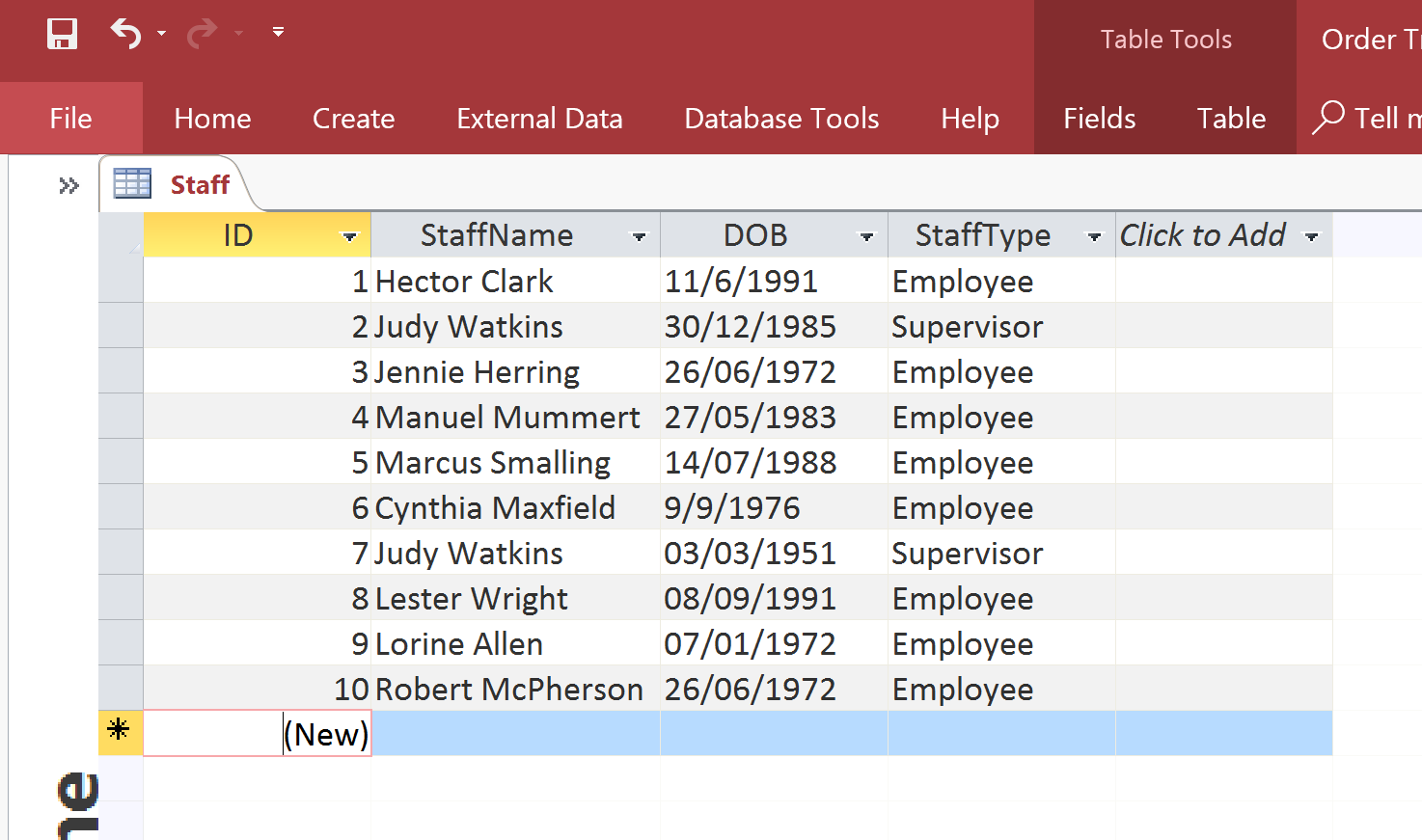 Staff Table
Staff Table
Please take notice of the StaffType field (there are two staff types – Employee and Supervisor). But who is supervising who(m)? It would be useful to know the supervisor of any given staff member so we need to add a field to track this information (StaffID). So, now our table looks like this:
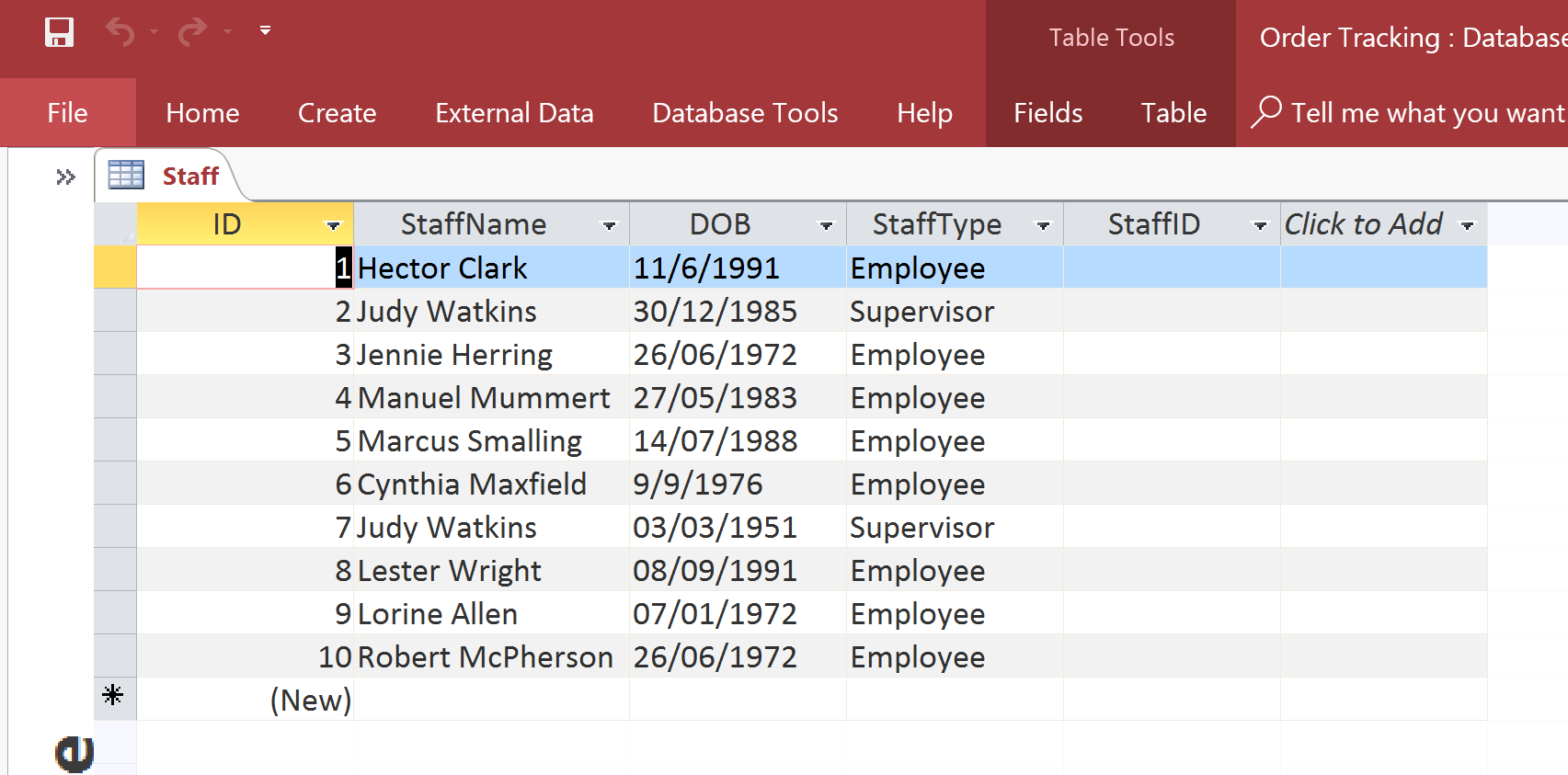 Staff table with StaffID field.
Staff table with StaffID field.
But what value do we put in the StaffID field? The Supervisor of any given staff member is also a staff member. That means that we need to put the ID of relevant record in the staff table. So, we have a field referencing another field in the same table. Is this even possible? And if it is, how do we do this?
Having seen that creating another table is often the solution to a data-modelling problem, we might be tempted to split the table into two tables – Employees and Supervisors. We could then link the Supervisors to the Employees and, voila, we have resolved our issue.
There are, however, several problems with this approach.
The first is that a member of staff would begin life in the Employee’s table and would then require moving to the Supervisor’s table if he/she got promoted. But should their record be deleted from the Employee’s table? What about any associated historical records? What about if there is a table to record sales or purchase orders or invoices and the Employee features here? The answer is that we cannot delete said employee from the Employee’s table.
We could, alternatively, leave them in the Employee’s table and simply add them to the Supervisor’s table (making sure that we do not use their Employee table entry in future transactions).
Hopefully, it is obvious that this is not a good solution as we will be duplicating data (another very obvious sign that you have a problem with your data-model).
OK, so if the above solution doesn’t work, what about adding a value to the StaffID field but not using a related table? This is actually a better solution than above but still not perfect. It would mean that we could enter any number in the StaffID field. Any number. We might, therefore, be able to add a StaffID number that doesn’t exist. Like this:
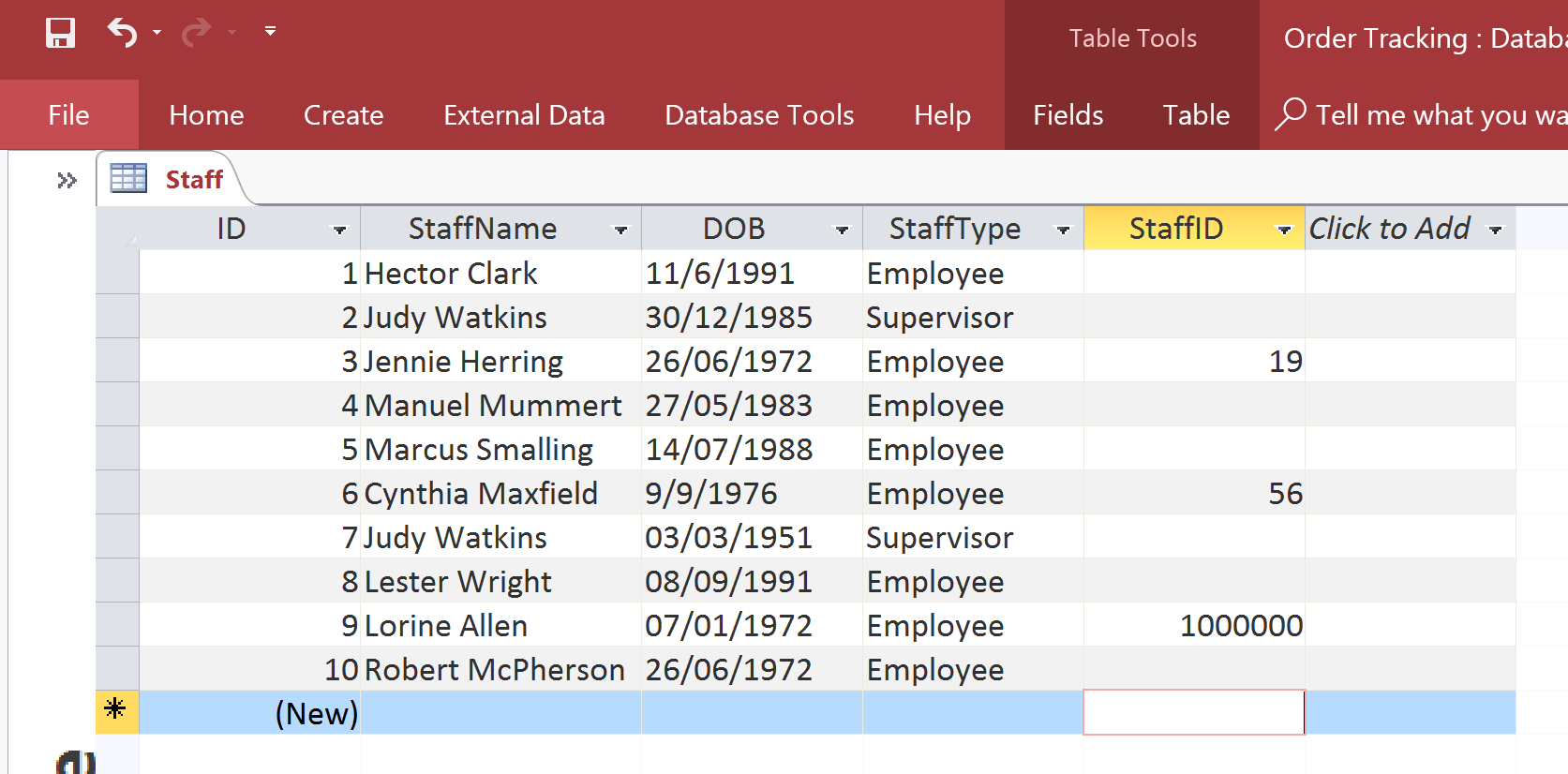 Staff Table with erroneous records
Staff Table with erroneous records
None of the Staff members have Supervisors that exist! We can safely say that they StaffID field adheres to the GIGO principle.
GIGO stands for “garbage in, garbage out”. The principle refers to the fact that if you allow garbage to be entered (such as a StaffID that doesn’t exist) you will get garbage as an ouput.
So, we want a single Staff table with a single StaffID field and we want to relate the StaffID field to the ID field of the same table! How do we do that? Simple.
 Go to the Database Tools tab and click on the Relationships button.
Go to the Database Tools tab and click on the Relationships button.
 Click the Show Table button.
Click the Show Table button.

Ensure that the Staff table is highlighted and then click the Add button.
You will now have the Staff table visible in the Entity Relationships Diagram. Here comes the complicated part so pay attention. Click the Add button…again!
 You will now have a Staff table and a Staff_1 table. Don’t worry, you haven’t duplicated the Staff table, just created a ghost copy of the table to make self-referencing possible.
You will now have a Staff table and a Staff_1 table. Don’t worry, you haven’t duplicated the Staff table, just created a ghost copy of the table to make self-referencing possible.
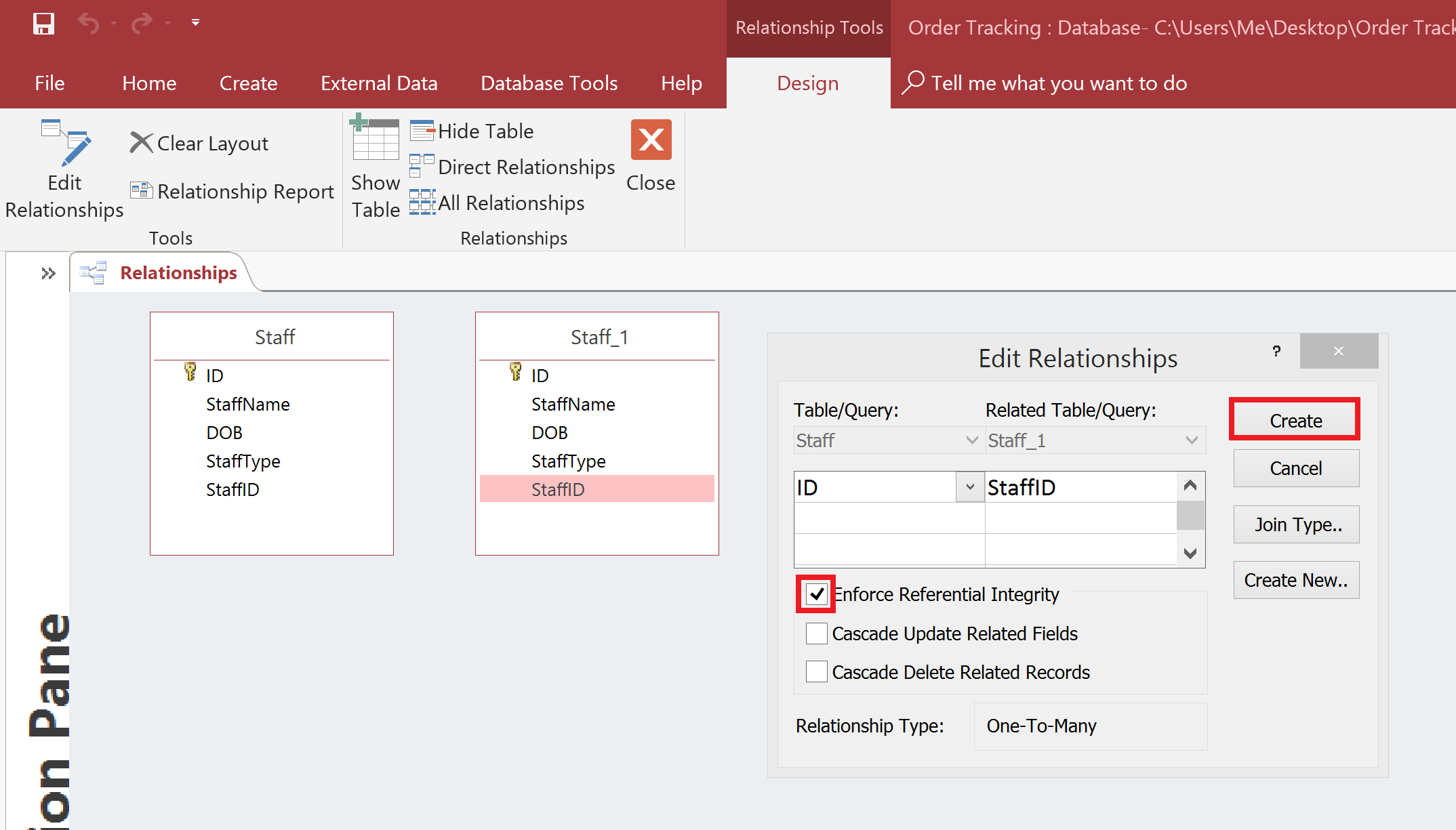 You can now click on the StaffID field in Staff_1 and drag it over to the ID field in the Staff table. Then check the Enforce Referential Integrity checkbox and click the Create button.
You can now click on the StaffID field in Staff_1 and drag it over to the ID field in the Staff table. Then check the Enforce Referential Integrity checkbox and click the Create button.
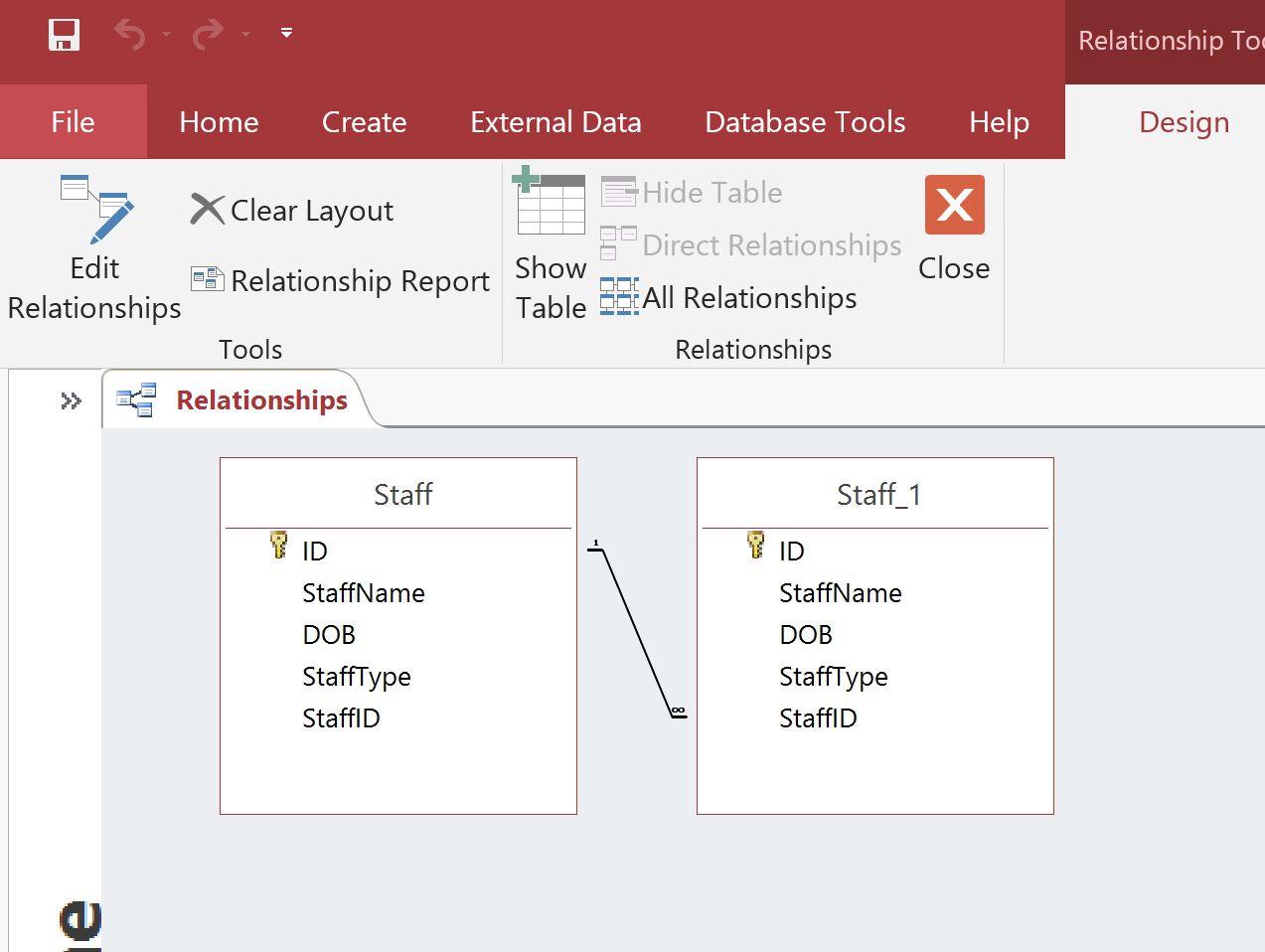 You will now have a self-referencing field in StaffID.
You will now have a self-referencing field in StaffID.
This now means that any value entered in the StaffID field will have to exist in the ID field of the Staff table. We have ensured relational integrity without having to alter the table structure.
The concept of a self-referencing table/field is not universal to MS Access. Any relational database system (MySQL, MariaDB, SQL Server to name but a few) allow self-referencing as standard.
5. Dummy Data
The next issue is very common and slightly tricky to describe but something that can cause serious headaches for prospective developers. It could be argued that it isn’t even a data-modelling issue as it doesn’t require any data-modelling! But it represents a common problem with those creating databases.
And that is: you must see entities for what they are at the lowest possible level.
This is a problem of conceptualisation more than design.
Let’s start, as usual, by outlining a scenario that requires a solution.
You are a specialist in the field of Mathmatics and work as a for-hire private math tutor. You prefer this to the daily grind of teaching a class of bored teenagers concepts such as quadratic equations and binary multiplication. When you first started teaching in schools, many years ago, you thought you would it more fulfilling but instead it frustrated you that the institutions that govered the school seemed to put barriers in your way and make teaching a more difficult endeavour than it needed to be. You grew increasingly disillusioned with the bureaucracy until one day you couldn’t take it anymore. So, you went out and bought a 2L bottle of cola, a packet of mints, some bicarbonate of soda, 3 kgs of lard, 42 rubber bands and a bottle of ear wax remover. Then you went to school the next day and …anyway…errr…suffice to say you are not a teacher anymore. You now provide private tutition which you bill for using a couple of Word invoices.
You have a lot of individual students (children mainly although some adults) whom you bill after every class. A typical invoice would look like this:
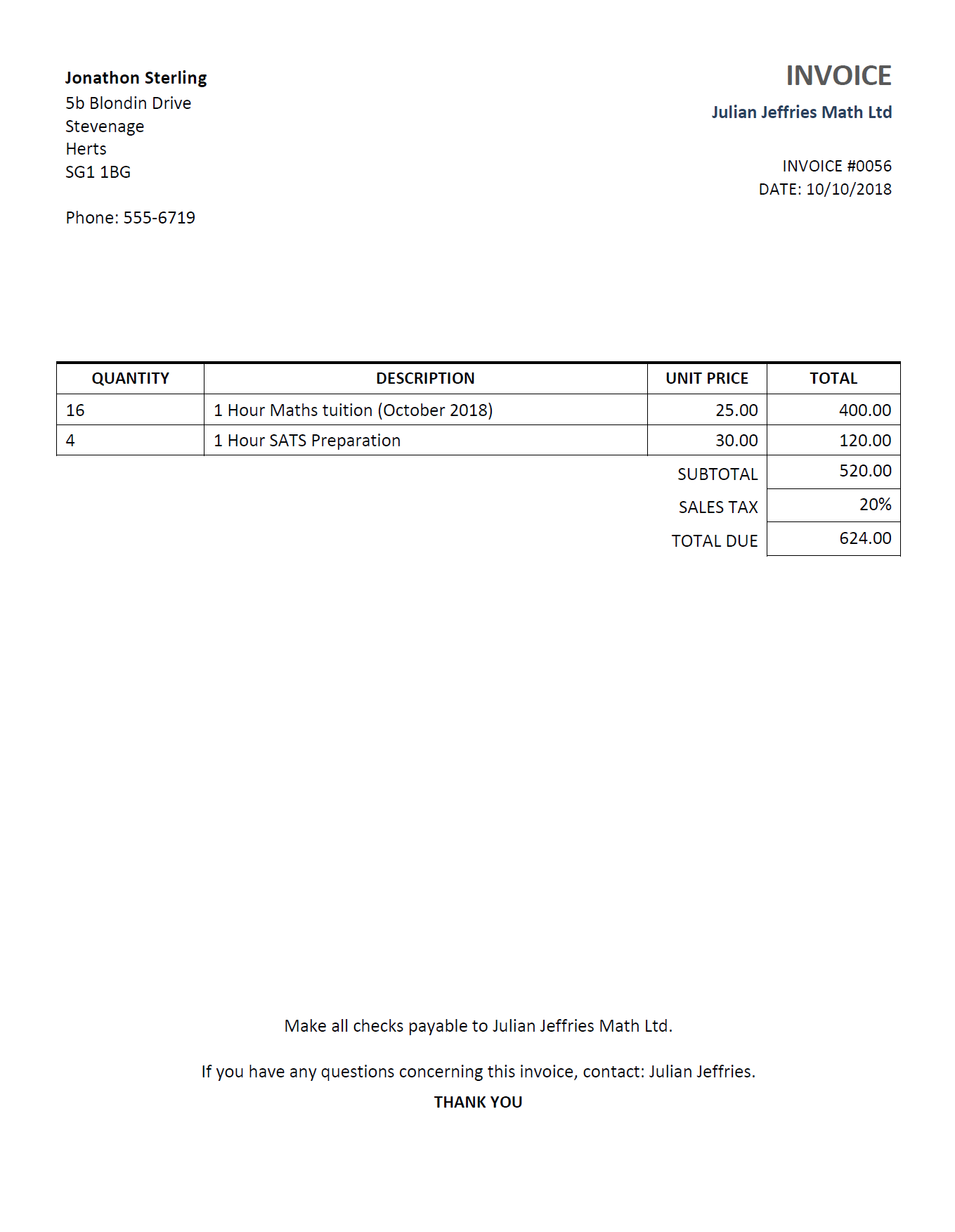 Invoice for Jonathon Sterling for 16 hours of Maths tuition in October 2018.
Invoice for Jonathon Sterling for 16 hours of Maths tuition in October 2018.
You also work on a contractual basis for a local after school club that provide classes of students extra tuition. A typical invoice for them would look like this:
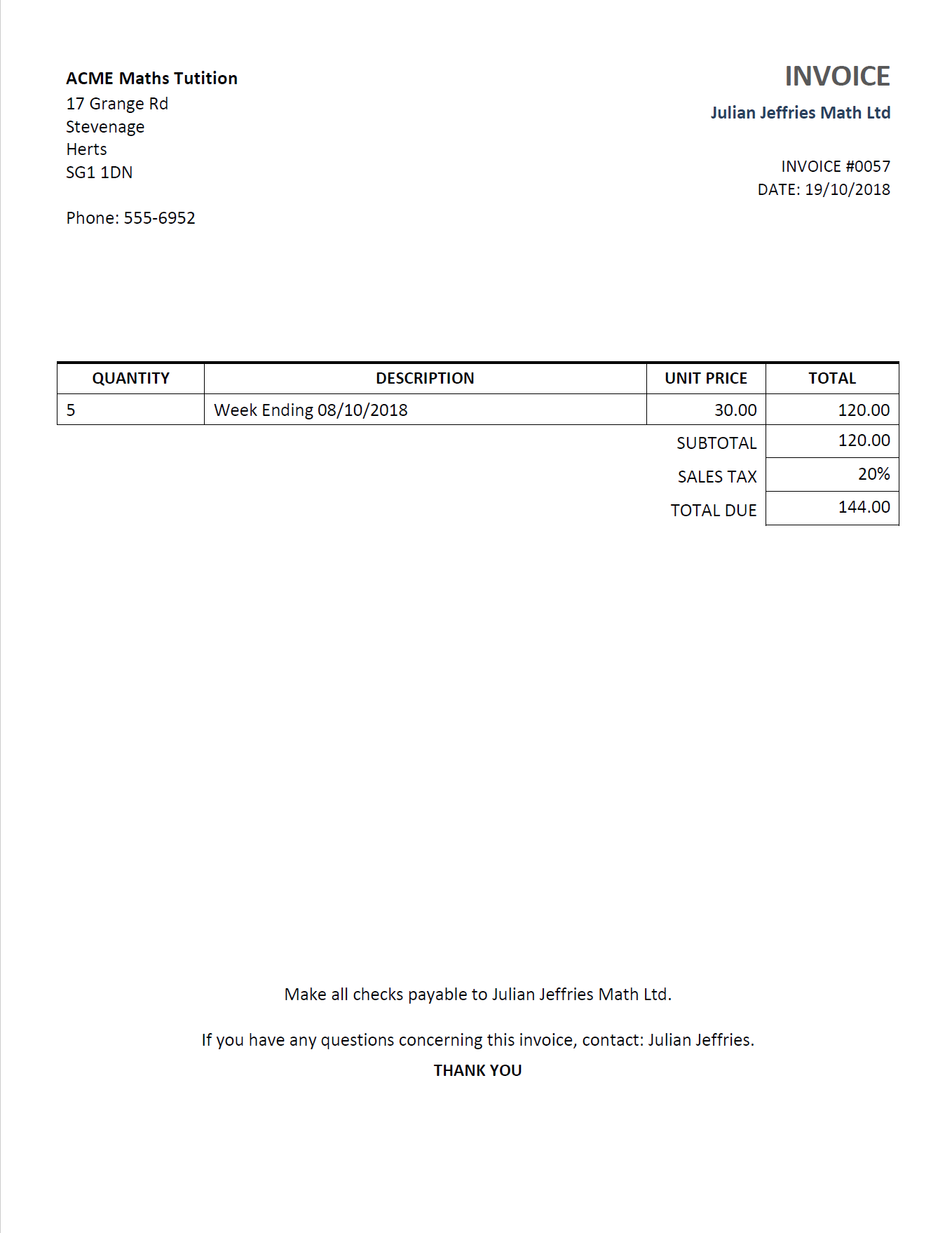 Invoice for local after school club ACME Maths Tuition
Invoice for local after school club ACME Maths Tuition
You, Julian Jeffries, are looking to get organised and wish to create a snazzy MS Access database to generate your invoices. You want to create an invoice report and be able to generate a nice looking invoice in no time at all!
Can you think of any potential problems with the two invoices above? And really think about this one.
The hard-to-spot but absolutely-necessary-to-spot problem is that you are making out invoices to 2 different entity types: Contacts (Jonathon Sterling) and Organisations (ACME Maths Tuition). It doesn’t feel like much of an issue but it can cause a surprising amount of pain if not thought about correctly.
Let’s keep things very simple and imagine the problem from the database level.
You have a Contacts table (to illustrate our point we will just use the name field):
Contacts
| ID | Name |
| 4 | Jonathon Sterling |
And you have an Organisations table:
Organisations
| ID | Name |
| 19 | ACME Maths Tutition |
And, of course an Invoices table (we also have an Invoice Lines table which we will not be showing here as it is not necessary to demonstrate our point):
Invoices
| ID | Date | Number | OrganisationID | ContactID |
| 23 | 10/10/2018 | 0056 | 19 | |
| 24 | 19/10/2018 | 0057 | 4 |
In the above Invoices table, because we are invoicing to different entity types, we have had to include the OrganisationID and ContactID.
Now, an obvious problem is which one to use for any given invoice (but we will assume you can hack some code together to fix that). But a less obvious problem is that it is possible to create an invoice with neither an OrganisationID nor a ContactID (remember the GIGO principle. This would mean that an invoice had no recipient.
And what about reports? How will you list the names of the Invoicees on the report? Again, more hacks will be necessary.
This system for making both Organisations and Contacts potential recipients is simply not working. But what should you do to fix it?
The answer is to think carefully about who you are and what service you are offering. Let’s focus on the Organisations. As stated, you are teaching at an institute that is called ACME Maths Tuition. You teach a class of students and ACME Maths Tuition pay you to do so (Julian Jeffries). ACME Maths Tuition earn their money by charging their students a fee to learn maths there. So we have 3 stakeholders to think about: Students that pay fees to an Academy (ACME Maths Tuition) which, in turn, pays a teacher (Julian Jeffries) to provide the service. To repeat: there are 3 stakeholders here.
If we attempt to analyse the situation in which Julian Jeffries teaches students “direct” we would say that we have 2 stakeholders: Students that pay fees and a teacher (Julian Jeffries). But, in fact, this second analysis is wrong. We still have 3 stakeholders, we just don’t know it. The stakeholders are: Students that pay fees to an Academy (Julian Jeffries Ltd) which, in turn, pays a teacher (Julian Jeffries) to provide the service.
The important thing to understand here is that it is necessary to conceptually think that Julian Jeffries Ltd (the Academy) and Julian Jeffries (the Teacher) are not the same entity. This might sound a little strange but think about this situation:
What happens if Julian Jeffries gets so busy that he needs to sub-contract other teachers to teach his pupils?
When thought of like this it becomes clear that the Academy (Julian Jeffries Ltd) is an Organisation that will accept student fees and then pay teachers to actually teach the students. One of the teachers that is on the books happens to be Julian Jeffries himself!
What does this mean for the data-model? It means that we are going to choose an Organisation and Contact for every invoice (these will be required fields). Let’s see how we do that.
The first thing to note is that we have an Organisation type which should be called “Academy” (so we can add that to the table) and that the first “Academy” in our table should be Julian Jeffries Ltd:
Organisations
| ID | Name | Type |
| 1 | Julian Jeffries Ltd | Academy |
| … | ||
| 19 | ACME Maths Tutition | Academy |
And what of Contacts. Well, we also have a Contact type which is “client”. Now, previously, all “clients” were the names of the individuals we were teaching. But what if we teach at ACME Maths Tuition? We need to add a “dummy” row to the contacts table. We will call our row “Multiple Students”:
Contacts
| ID | Name | Type |
| 1 | Multiple Students | Client |
| … | ||
| 4 | Jonathon Sterling | Client |
And, finally, our invoices table will now look like this:
Invoices
| ID | Date | Number | OrganisationID | ContactID |
| 23 | 10/10/2018 | 0056 | 19 | 1 |
| 24 | 19/10/2018 | 0057 | 1 | 4 |
Conceptually, this is the right approach. When the Organisation is Julian Jeffries Ltd, we want to know exactly which Contact is being taught (as this is the person we are billing). But when the Organisation is an Academy like ACME Maths Tuition, we don’t need the names of the Contacts so we use Multiple Students (Contact ID: 1). This use of dummy data is often the only viable way to create a workable data-model.
There is, however, one more thing that we need to do. We will need to ensure that the invoicee is correctly identified. If the Organisation is an Academy like ACME Maths Tuition, then we want to invoice ACME Maths Tuition (and the associated address fields). If the Organisation is Julian Jeffries Ltd, then we want to use the name of the Contact and its associated fields. You have a couple of options to do this.
One might be to simply have 2 different invoices (1 that uses the Organisation as the invoicee and the other that uses the Contact as the invoicee). Although it might seem odd to have 2 different invoices, it is not a terrible idea as there is no reason that an invoice for an Academy should look the same as an invoice for a Client.
Another option would be to write a select query that queries the relevant data depending on the value of the OrganisationID (this way you will only need one invoice). But you will need to know how to use the Query Builder so it may be easier to create separate invoices.
The need for dummy records is very prevalent in business. You might sell cars and have agencies that find you prospective clients and also have the potential for walk-in clients. In this case, you are also an Agency. Make sure you build your database accordingly.
Summary
Writing the correct data-model is a very difficult task but one which must done prior to the creation of other Access objects and taken seriously. One hour spent data-modelling now can be worth ten hours not having to fix issues going forward.
And now for an oft-asked question:
How do I know if my data-model is correct?
The answer is that it is easier to know if it isn’t correct than if it is. Whilst data-modelling, ask yourself these questions:
- Am I duplicating data (Employees and Supervisors tables instead of a single Staff table)?
- Am I putting single values in every field (no mulitple telephone numbers)?
- Am I expanding my tables down, not across (no 4 email address fields for an Organisation)?
- Am I wasting space (think carefully about which fields should and should not allow null values)?
If you consistently ask yourself the above questions, you will find it much easier to see that you have gone wrong. Fixing it, however, is another matter…
Remember to start with Outputs (reports) and work backwards. Be on the look-out for tell-tale signs that your data-model is not correct. If it isn’t, bite the bullet and fix it.
Don’t ignore it.
The longer you ignore it, the greater the eventual fix will be. And you will need to fix it eventually.
The absolute best I have yet come across. The clearest, most respectful communication. Still astonished at the insights (‘because you were unwise enough to tell your boss you’d make a database’. EXACTLY. ‘Normalisation…atomised….partial dependencies…1st Normal Form blah blah’. YEP, THAT’S HOW IT’S BEEN. Thank you for putting that in proper practical perspective and giving me understandings and a bridge from that to application.
This tute occupies the perfect, much needed mid ground between all those beginners’ instructions and the hard core coding stuff. I think you might just have saved my sanity. Was starting to wonder when/where a/the key might be to getting to grips with this.
Hi Ned
Thanks for the comment.
I created this post because I get a lot of questions from users about problems they are having with their databases and the root cause of the issue is, very often, data-modelling. Now I can just respond with the link to this post.
Bad data-modelling is a very understandable problem but of all the technologies out there, MS Access is the WORST for dealing with an inferior data model. Although this sounds bad, I actually think it is a good thing as it forces users to attempt to better understand the art of data-modelling and how to think about the logical objects that they are creating.